

Step-by-Step Big O Complexity Analysis Guide, using Javascript


When you get familiar with the common Big O complexities, you have a good base on how to look at the algorithms & operations you deal with.
If you need a quick refreshment for the common Big O complexities, take a look here:
Comprehensive Big O Notation Guide in Plain English, using Javascript
In most guides, including the one I wrote above - you will see very specific and simple examples choosed for the sake of explaining. In a real world application, the functions / algorithms you will face won't always look like the examples. There will be functions having inner functions, declaring local scope variables, mutating values and so on. This type of algorithms includes several types Big O complexities.
The main goal is no matter how many complexity types a method includes - we always want to reduce everything into one end result.
How can we simplify this? By using an approach that includes 3 main steps:
1 - Analyse and break your function into individual operations.
2 - Calculate the Big O of each operation one step at a time.
3 - Add Big O of each operation together and calculate the end result.
And while going through those steps, we will keep 4 rules in mind:
1 - Always assume the worst case.
2 - Each input should have a unique variable.
3 - Drop the constants.
4 - Drop non-dominant terms.
In a visual representation, approach we will use looks like this:

Now we have a roadmap. Before diving into fully following the steps - let's figure out how to apply these 4 rules first. Then we will be also taking a short look at how to calculate space complexity before doing a case study at the end of this article: analysing both time and space complexity, then optimizing a functions runtime.
Always assume the worst case
Big O notation can be used to find best, average and worst cases. But when it comes to programming, we are more interested on the worst case part. Because we want to know what could be the worst case when it comes to scaling. When we know the worst case, we can optimize our algorithms further if it is needed.
Let's take a look at an example. We have a store which has about 10000+ unique products. We need a simple function just to check price of a product with a given name in the list. So here we have a function that handles product lookup:
const productList = [
{ name: 'Laptop', price: 18487 },
{ name: 'Keyboard', price: 356 },
{ name: 'Monitor', price: 8345 },
// ...assuming 10000 more items here in between
{ name: 'Tablet', price: 9875 },
]
function lookupPrice (name, list) {
for (let i = 0; i < list.length; i++) {
if (list[i].name === name) {
console.log(`Price of '${list[i].name}' is: ${list[i].price}`)
break;
}
}
}
lookupPrice('Monitor', productList)
// => OUTPUT: "Price of 'Monitor' is: 8345"
What is happening in the code?
lookupPricefunction iterates each element in the list until it finds the product with target name.- When it finds the target - prints it's name & price, then stops the execution.
On this example, we choosed a product that was at the index[2]. In other words, we got done with the operation at the 3rd step. Pretty good, right?
But we can't assume this function will always work with the same level of speed by it's nature. Because we just want to lookup to a product price by using it's name in the list, which can be any of them. We should also take the number of products into account, they can change in future. For example today we have 10000+, maybe tomorrow we will have 50000+ products. What can be the worst case here?
It would be choosing a product name which happens to be at the last index in the array. In that case function must iterate through all unmatching indexes to find the result - and that would be the worst case.
In other words, we can confidently say the worst case depends on the array length here - which translates into Linear time O(n)
Each input should have a unique variable
Whenever you are analyzing a function that operates with multiple inputs, always make sure to assign a unique variable name representing each input.
Example:
const numbers = [1, 2, 3, 4]
const letters = ['a', 'b']
function printLists (listOne, listTwo) {
for (let i = 0; i < listOne.length; i++) {
console.log(listOne[i])
}
for (let i = 0; i < listTwo.length; i++) {
console.log(listTwo[i])
}
}
printLists(numbers, letters)
/*
OUTPUT:
1
2
3
4
a
b
What would be the Big O of printLists function here? You maybe thinking, at the first look I am seeing for loops there, it has something to do with Linear time O(n), right?
While we are on the right track with Linear time, let's not forget dealing with 2 different inputs situation. In terms of Big O, the 'n' always must have a meaning. When we have a single input, 'n' is a common naming convention for it.
When it comes to several inputs, you need to give them unique names - and that's for a good reason you will soon see why. In fact you can give them any names since they are variables, but common naming convention is giving letter names with an alphabetical order.
If you have 2 different inputs, you can name them 'a' and 'b'
If you have 3 inputs, you can name them 'a', 'b' and 'c', and so on.
Let's calculate the Big O of the printLists function:
// function recieves 2 different inputs, let's call them 'a' and 'b'
function printLists (listOne, listTwo) {
// iterates through input 'listOne' -> O(a) Linear time
for (let i = 0; i < listOne.length; i++) {
console.log(listOne[i])
}
// iterates through input 'listTwo' -> O(b) Linear time
for (let i = 0; i < listTwo.length; i++) {
console.log(listTwo[i])
}
}
// End result for Big O => O(a + b)
Now this may seem like a bit confusing. What does O(a + b) mean? Let me explain with steps:
- printLists takes 2 different inputs (lists)
- Loops through the first list - This part has a linear time complexity
- Loops through the second list - This part has a linear time complexity
At the end, this function runs linear times, but the detail here is we can't just call this out as O(n) . Don't forget the second list have to wait until the looping first list is done. Therefore this can be translated as:
O (a) -> linear time to finish execution on first input
O (b) -> linear time to finish execution on second input
O (a + b) -> It takes both linear times to completely finish the execution.
You may have 2 elements on the first list, but second list maybe have a million items. We don't know since they are used as variables and we don't want to focus on that. All we want to focus here is to see the scaling patterns.
Okay, now you may ask "What if we have a nested loop with 2 different inputs?"
Example:
const drinks = ['water', 'coffee']
const persons = ['person 1', 'person 2', 'person 3', 'person 4']
// function recieves 2 different inputs, let's call them 'a' and 'b'
function servingDrinks(drinkList, personsList) {
// iterates through input 'drinkList' -> O(a) Linear time
for (let i = 0; i < drinkList.length; i++) {
// iterates through input 'personsList' -> O(b) Linear time
for (let j = 0; j < personsList.length; j++) {
console.log(`Gives ${drinkList[i]} to ${personsList[j]}`)
}
}
}
servingDrinks(drinks, persons)
// End result for Big O => O (a * b)
/*
OUTPUT:
'Gives water to person 1'
'Gives water to person 2'
'Gives water to person 3'
'Gives water to person 4'
'Gives coffee to person 1'
'Gives coffee to person 2'
'Gives coffee to person 3'
'Gives coffee to person 4'
*/
Taking a closer look at the complexities:
O (a) -> linear time to finish execution on first input
O (b) -> linear time to finish execution on second input
O (a * b) -> It takes 'a' times 'b' linear times to completely finish the execution, because they are nested. On this example we have passed 2 drinks and 4 persons to serve respectively. As seen on the output, we are getting 2 x 4 = 8 iterations on total.
One more reminder, don't confuse this one with two nested loops iterating the same collection. In that case the Big O is called Quadratic time O(n ^ 2). Just make sure to double check whenever you see 2 nested loops, it doesn't always mean they loop through the same list!
Quick reminders:
- Looping through 2 seperate arrays one after another =
O(a + b)Any step that happens one after another, we add them => + - Looping through 2 nested seperate arrays =
O (a * b)Any step that is nested, we multiply them => *
Loops using same input:
- Looping through same array one after another =>
O(n + n)=>O(2n)=>O(n)or Linear Time (See the calculation details on the next section) - Looping through same array with 2 nested loops =
O(n ^ 2)or Quadratic Time
Drop the constants
Our main goal is to figure out how things are scaling roughly on the long term. When we talk about the constants, we know the fact they don't change no matter how big is the input size - and that's a reason why we drop them at the end. Because a constant part combined with other complexities doesn't have an impact on scaling when we are looking for a pattern.
Example:
const numbers = [1, 2, 3, 4, 5, 6]
// function recieves a single input
function printFirstHalf (list) {
// iterates through list -> O(n) Linear time
for (let i = 0; i < list.length / 2; i++) {
console.log(list[i])
}
}
printFirstHalf(numbers)
// Big O total => O (n / 2)
/*
OUTPUT:
1
2
3
*/
What would be the Big O of printFirstHalf function?
Again - it has a linear time, but with one interesting part: only iterates the half length of the array. Therefore we can call the Big O total of this function as: O (n / 2)
But we are not done yet. If you look at this function second time, even it goes through the half of the list - execution time is still dependent on the input length. In the long term, pattern wise it is still directly linked to the length of input.
In this case we just drop the constant part:
O (n / 2) -> drop the constant (2) -> end result = O (n)
Another example:
const numbers = [1, 2, 3]
// function recieves a single input
function printTwiceForNoReason (list) {
// iterates through list -> O(n) Linear time
for (let i = 0; i < list.length; i++) {
console.log(list[i])
}
// iterates through the same list again -> O(n) Linear time
for (let j = 0; j < list.length; j++) {
console.log(list[j])
}
}
printTwiceForNoReason(numbers)
// Big O total => O (n + n) => O (2n)
/*
OUTPUT:
1
2
3
1
2
3
*/
Here we have 2 loops going through same list one after another, at the end we are ending up with O(n + n) since we are using the same list.
Note: Whenever you see the same input used one after another, you can shortly define them as follows:
O(n + n) => O(2n)
O(n + n + n) => O(3n), and so on.
Let's calculate:
O(n + n) => 'n' s here can be shortly defined as 2n => O(2n) => now drop the constants => O(n)
Just remember: When adding complexities together, we define the constant values with numbers and scalable parts with variable names (letters). Whenever you end up with a bunch of letters and numbers, know that those will be removed to only focus on the scaling pattern.
Drop non-dominant terms
This rule is directly related to the first one: "Always assume the worst case". Essentially, what we do here is to compare all existing complexities we have, then pick the worst scaling one - in other words the "dominant term". This is typically the last rule being used to finalize a complexity analysis of an algorithm.
Example:
const fruits = ["apple", "strawberry", "watermelon"]
// function recieves a single input
function printAndPair (arr) {
// iterates through list -> O(n) Linear time
for (let i = 0; i < arr.length; i++) {
console.log(arr[i])
}
// declares variable -> O(1) Constant time
const totalPairs = arr.length * arr.length
// prints given value -> O(1) Constant time
console.log('Estimated paired elements length:', totalPairs)
// nested loop using the same array -> O(n ^ 2) Quadratic time
for (let j = 0; j < arr.length; j++) {
for (let k = 0; k < arr.length; k++) {
console.log(`${arr[j]} - ${arr[k]}`)
}
}
}
printAndPair(fruits)
// Big O total => O (n) + O(1) + O(1) + O(n ^ 2)
/*
OUTPUT:
'apple'
'strawberry'
'watermelon'
'Estimated paired elements length:' 9
'apple - apple'
'apple - strawberry'
'apple - watermelon'
'strawberry - apple'
'strawberry - strawberry'
'strawberry - watermelon'
'watermelon - apple'
'watermelon - strawberry'
'watermelon - watermelon'
*/
As we see in the function, we have 4 operations with various time complexities in following order:
O (n) + O(1) + O(1) + O(n ^ 2)
Now let's see how to get a single result out of this.
Step 1 - Start with adding all constants together:
O (n) + O(2) + O(n ^ 2)
Step 2 - Now we only see different types of complexities. Remember the rule with constants? Let's remove them:
O (n) + O(n ^ 2)
Step 3 - At this step we are looking at 2 different non-constant time complexities. There is only one question to ask here: "Which one scales worse?"
Since O(n ^ 2) - Quadratic time scales much worse than O (n) - Linear time, we simply pick the O(n ^ 2) as the final result and drop the non-dominant O (n).
Result is: O(n ^ 2)
Analyzing space complexity
Up to this point, we have been only focused at time complexity part of the Big O analysis. You maybe now thinking "How do we calculate the space complexity? Do we need another full guide for it?"
Don't worry, all the rules of Big O that we went through also applies to calculating space complexity. We just need to know one thing: Where to look. But before we learn where to look, let's have a brief look at how things work under the hood - with that we can understand why we look at certain parts in the code.
When we are talking about space complexity, we are actually talking about the memory.
Our Javascript code runs by a Javascript Engine under the hood. This engine has a memory with 2 places in order to save and remember things to run our code: Memory Heap and Call Stack.
Take a look at this graph to see what are the things being stored inside them:
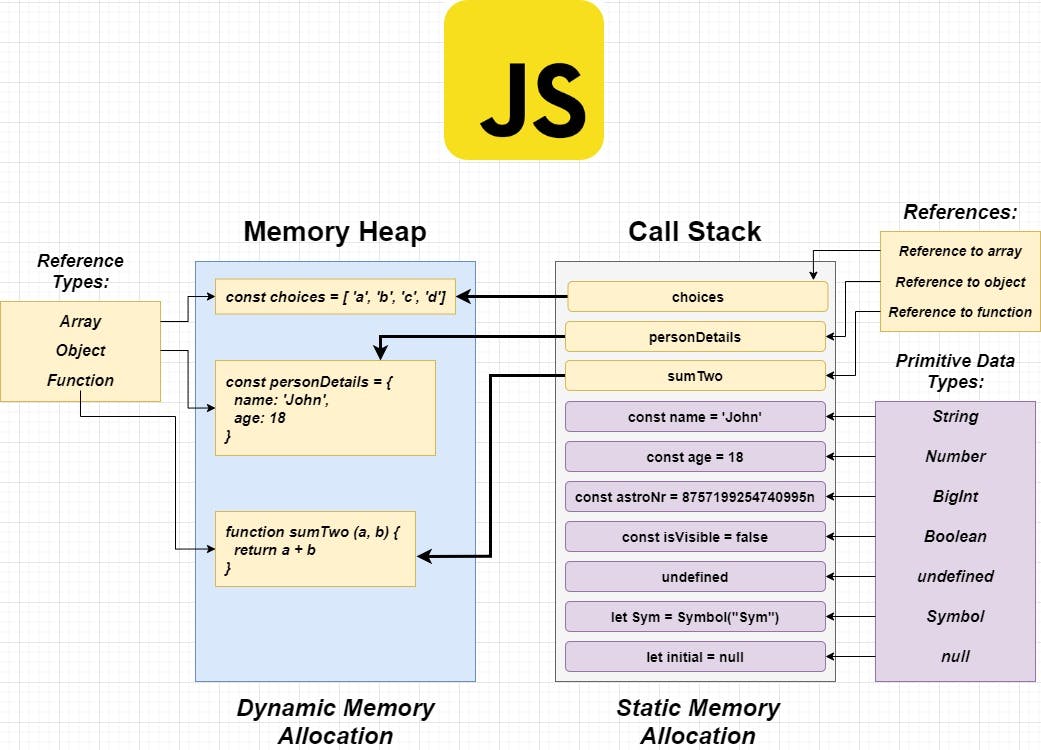
As you can see, whenever we declare a variable, create an object, array, or call a function, we are actually using the memory. Where do they end up is totally based on their type.
Call stack - Primitive types and References (pointers for arrays, objects and functions that are inside the Memory heap) are stored inside the Call Stack. Call stack also keeps track of execution order, in other words what is happening in our code line by line. It operates in FILO (First In Last Out) mode.
Memory Heap - In the Memory Heap we got arrays, objects and functions - or shortly non-primitive types. In fact if we go deeper we can actually say only objects, because in JS both arrays and functions are also objects in essence (but let's save the further details on those for another article).
In Javascript we don't need to manually allocate the memory, it is handled internally under the hood - but still we need to be careful.
Have you ever seen an error like this before? I bet you probably did:

I remember seeing this a lot when I was studying loops. This is most likely caused by an infinite loop. This error is also called Stack Overflow (quite familiar name, isn't it?). It happens when there are way too many function call references that exceeds the memory limit of the Call Stack.
Main point here is even the memory management being taken care by JS Engine under the hood, we still don't have infinite resources - and still can run into memory problems if we are not careful.
Now we have some brief knowledge about how things are stored, we can move forward to figuring out where do we look at during calculating space complexity. In the big picture, total space complexity is the sum of both Auxiliary space and Input size:
Auxiliary space - It refers to the temporary memory space required by an algorithm to be used (while it is executing)
Input size - It refers to the input size that function receives. (this input already exists somewhere in memory)
But when we are analyzing space complexity of an algorithm, our focus is on the Auxiliary space part: which is the temporary space required while running the algorithm. If you specifically need to include the input size for a reason, then your total space complexity analysis will be based on the total Auxiliary space + Input size.
When you are looking for Auxiliary space complexity, just ask yourself this question:
"Does this function add any new spaces in memory while running the algorithm?"
Things that cause space complexity:
- Variables
- Allocations
- Data structures
- Function calls
Let's take a look at couple examples:
Example:
const numbers = [1, 2, 3, 4, 5, 6]
function getTotal (arr) {
// Declares variable - let total -> O(1)
let total = 0
// Declares variable - let i -> O(1)
for (let i = 0; i < arr.length; i++) {
total += arr[i]
}
return total
}
// Big O space complexity => O(1) + O(1) => O(2) = O(1) Constant
getTotal(numbers) // OUTPUT => 21
In the above function we recieve a list a list of numbers to get their sum. How much space do we create? We declare 2 variables. Now you maybe thinking, "How about the "i" variable, it changes on each step? Wouldn't it be Linear in this case?"
Since we are focused on extra space, i we have here is being re-used - in other words we don't add more space for it. Therefore we have O(1) - Constant space here.
Example:
const guests = ['John', 'Jane', 'Adam', 'Olivia', 'Alan', 'Amy', 'Joe']
function bookTables (list) {
// Declares variable - let tables -> O(1)
let tables = []
// Declares variable - let i -> O(1)
for (let i = 0; i < list.length; i++) {
// Pushes values based on the list length - O(n)
tables.push(`Table ${i + 1} is reserved for ${list[i]}`)
}
return tables
}
// Big O total => O(1) + O(1) + O(n)
// Big O space complexity after dropping constants => O(n) Linear
const bookedList = bookTables(guests)
console.log(bookedList)
/* OUTPUT:
[
'Table 1 is reserved for John',
'Table 2 is reserved for Jane',
'Table 3 is reserved for Adam',
'Table 4 is reserved for Olivia',
'Table 5 is reserved for Alan',
'Table 6 is reserved for Amy',
'Table 7 is reserved for Joe'
]
*/
In this example we are creating extra memory by pushing transformed the values into the new array we created. Since the amount of values to be pushed are dependent on the length of the input - our space complexity is O(n) - Linear space.
Example:
function fibonacciRecursive(num) {
// exit conditions, return if it is 0 or 1
if (num === 0) return 0
else if (num === 1) return 1
// else, call the function recursively
else return fibonacciRecursive(num - 1) + fibonacciRecursive(num - 2)
}
fibonacciRecursive(4)
// OUTPUT => 3
Now this one is a little bit tricky - because it has something to do with how Call Stack works. If you remember, this recursive approach had a O(n ^ 2) Quadratic time complexity, but space complexity here is O(n).
But why? As I have mentioned earlier, Call Stack operates in a FILO (First In Last Out) fashion. If we look closer to this line again:
else return fibonacciRecursive(num - 1) + fibonacciRecursive(num - 2)
Space complexity here depends on the number of active function calls during runtime (function that is still in the stack). Even we are calling 2 functions one after another, O(n) space is being used when fibonacciRecursive(num - 1) is calculated. Because when the execution is done, it pops out from Call Stack. Then the empty space left from fibonacciRecursive(num - 1) is now can be used by fibonacciRecursive(num - 2) that comes right after it.
I hope these examples shed some light upon space complexity!
Case study: Two Sum
Our case study is a classic LeetCode challenge called Two Sum, now we can apply our Big O analysis knowledge that we have learned so far:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
If you ever get this question on a technical interview, a good question to ask would be: "Is this array sorted or not?"
Approach we are going to choose will differ based on that, but we are going to take a look at how to handle both possibilities. The goal is to return the indexes of 2 numbers that they add up to a specific target.
We can start with assuming the array is unsorted. First solution comes to mind is to use Brute force using nested loops:
const unsortedNrs = [4,2,6,3,1,5,9,7,8,10]
const twoSumBrute = (list, target) => {
for (let i = 0; i < list.length; i++) {
for (let j = 0; j < list.length; j++) {
if (list[i] + list[j] === target) {
return [i, j]
}
}
}
}
twoSumBrute(unsortedNrs, 7)
// OUTPUT => [0, 3]
What would be the Time & Space complexity here? If we start with time, we see nested loops iterating through the same array. Which means we have O(n ^ 2)- Exponential time.
When we look at the space complexity, we got only 2 variables: let i and let j. We see that they are being re-used and not adding more spaces. Which means we have O(1)- Constant space.
Result:
- Time Complexity:
O(n ^ 2)- Quadratic time - Space Complexity:
O(1)- Constant space
But this doesn't look good. If we had to go through 1000 items, we had to iterate a million times! Let's focus on improving time complexity. Common approach to improve nested loops is to use Hash Maps (Javascript Objects are actually Hash Map equivalents under the hood inside JS Engine)
const unsortedNrs = [4,2,6,3,1,5,9,7,8,10]
const twoSumHashmap = (list, target) => {
const lookupTable = {}
// build a lookup table
for (let i = 0; i < list.length; i++) {
lookupTable[list[i]] = i;
}
// iterate
for (let j = 0; j < list.length; j++) {
let diff = target - list[j]
if (lookupTable[diff] && lookupTable[diff] !== j) {
return [j, lookupTable[diff]]
}
}
}
twoSumHashmap(unsortedNrs, 7)
// OUTPUT => [0, 3]
What would be the Time & Space complexity here? To start with, now we don't see any nested loops anymore. Instead, we got 2 loops goes one after another. It's definitely an improvement. Why?
O(n + n) => O(2n) => (drop the constants) => O(n) - Linear time
We just reduced our time complexity from Quadratic to Linear! In other words, if we had 1000 items, in worst case we can get done with 2000 iterations due to 2 loops coming one after eachother. On first example we needed to iterate a million times. Both functions are doing the exactly same thing, but the efficiency difference is huge.
How about space complexity? It is not O(1) - Constant anymore. Because we have used an Object as a buffer by storing list values, which improved the lookup time greatly. Instead of iterating the whole array on each index with a nested loop, now we have one iteration that can do a constant time lookup. If you take a closer look at the first loop, you will see the object size is based on the length of the list. Therefore, we got O(n) - Linear space.
I believe this is a great example of how tradeoff between Time and Space complexity looks like. We have sacrificed some space in memory to be able to improve our time.
Result:
- Time Complexity:
O(n)- Linear time - Space Complexity:
O(n)- Linear space
Now, let's assume the array we got is an ordered one. In fact the solutions we just saw can work on both sorted and unsorted lists. Can we optimize this algorithm even further? When we need to deal with an ordered list in a situation like this, we can also use a technique called "Two pointer technique"
const sortedNrs = [1,2,3,4,5,6,7,8,9,10]
const twoSumUsingTwoPointers = (sortedNums, target) => {
let left = 0;
let right = sortedNums.length - 1;
while (left < right) {
let sum = sortedNums[left] + sortedNums[right];
if (sum === target) {
return [left, right];
} else if (sum < target) {
left++;
} else {
right--;
}
}
}
twoSumUsingTwoPointers(sortedNrs, 7)
// OUTPUT => [0, 5]
What would be the Time & Space complexity here? Since the array is sorted, we know that nothing can be smaller than the first array item (left) and there is nothing can be bigger than the last array item (right). In this case instead of one pointer, we use 2 pointers, one starts from the beginning (left) and one starts from the end (right) moving towards the middle - until the sum of left and right values are equal to the sum.
Scaling of this operation is based on the array length, so we have O(n) - Linear time complexity. Regarding space complexity - we only create 3 variables here: left, right and sum. Since they don't cause any memory growth, our space complexity here is Constant space - O(1)
Result:
- Time Complexity:
O(n)- Linear time - Space Complexity:
O(1)- Constant space
As a final note, you have probably noticed that I haven't used any built-in JS methods like (forEach, map, filter, etc.) on my examples. Because I wanted to keep the examples as plain as possible.
In a typical day-to-day job, most JS developers uses modern built-in methods for JS. If you also add using methods from libraries / frameworks, you will notice that we have a lot of abstractions upon abstractions on top of eachother.
Now you maybe thinking "How am I going to handle doing a Big O Complexity analysis in this case?"
There is only one way: you will just need to dig deeper into how that method is built and figure out it's time & space complexity. If you are using a built-in JS method, you need to figure out what is the time & space complexity of that method inside the JS Engine. If you are using a method from a library, it is the same thing: you just need to figure out how that method is being built in that library.
If you keep this in mind, it can help you to look at the things you use in a different way. Big O is something universal, having this knowledge will always help you to finding an answer to this question: Why should you choose one data structure / algorithm over the another.
I hope this article helped you to understand how to perform Big O Time and Space complexity analysis. Thanks for reading!